
图 1:JiT-B/16 在 ImageNet 256×256 上的生成样例。
Back to Basics: Let Denoising Generative Models Denoise 的 PyTorch/GPU 复现结果展示页
本页侧重:可视化样例、FID/IS 指标,以及与传统扩散模型的差异说明。
本节结合源码与原论文 《Back to Basics: Let Denoising Generative Models Denoise》(Li & He, 2025)梳理 JiT 的总体设计思路。
本节对照代码与论文,逐步梳理 JiT 的训练数据流。每个阶段都给出“代码片段 → 数学公式 → 数据流动”的映射,方便交叉验证。
main_jit.py)# main_jit.py
transform_train = transforms.Compose([
transforms.Lambda(lambda img: center_crop_arr(img, args.img_size)),
transforms.RandomHorizontalFlip(),
transforms.PILToTensor()
])
dataset_train = datasets.ImageFolder(os.path.join(args.data_path, 'train'),
transform=transform_train)
数据流:ImageNet 原图 → 中心裁剪到 img_size → 随机水平翻转 → 转为整型 Tensor(范围 [0,255])。此时尚未归一化。
engine_jit.py::train_one_epoch)# engine_jit.py
x = x.to(device, non_blocking=True).to(torch.float32).div_(255)
x = x * 2.0 - 1.0
labels = labels.to(device, non_blocking=True)
对应公式:
$$ x_{\text{norm}} = 2 \cdot \frac{x_{\text{uint8}}}{255} - 1 \in [-1,1] $$即把像素映射到 [-1,1],并与标签一起传入 Denoiser(分布式 DDP 包装后的模型)。
denoiser.py::forward)t = \texttt{sample\_t}(B) # sigmoid(𝒩)
e = torch.randn_like(x) * self.noise_scale # 噪声
z = t * x + (1 - t) * e # 线性插值
v = (x - z) / (1 - t).clamp_min(self.t_eps) # 目标速度
x_pred = self.net(z, t.flatten(), labels_dropped)
v_pred = (x_pred - z) / (1 - t).clamp_min(self.t_eps)
公式与数据流:
# denoiser.py
loss = (v - v_pred) ** 2
loss = loss.mean(dim=(1, 2, 3)).mean()
数学描述:
$$ \mathcal{L}_{\text{JiT}} = \mathbb{E}_{x, e, t}\left[\left\|v - v_\theta(z,t,y)\right\|_2^2\right], \quad v = \frac{x - (t x + (1-t)e)}{1 - t} $$该损失与论文中提出的“仅回归速度”的思想对应,训练与采样共用 $v$。
# engine_jit.py
optimizer.zero_grad()
loss.backward()
optimizer.step()
model_without_ddp.update_ema()
优化器使用 AdamW(main_jit.py 中设置),EMA 更新在 denoiser.py::update_ema 中按 $m \leftarrow \alpha m + (1-\alpha)\theta$ 形式维护两个时间常数,供采样时切换。
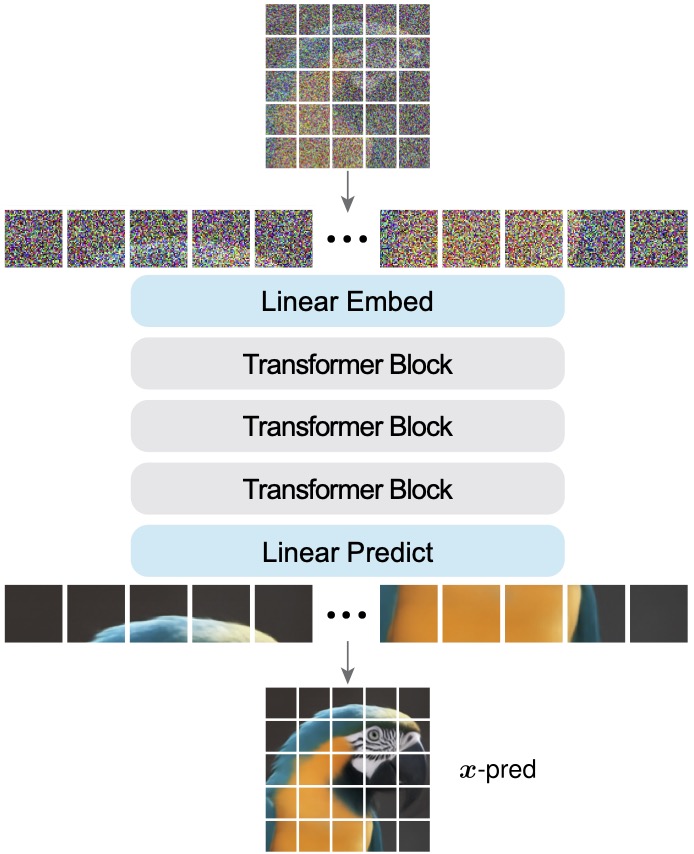
main_jit.py)。engine_jit.py)。denoiser.py)。下面以 denoiser.py::generate 及其辅助函数为线索,讲解“如何从纯噪声生成高质量图像”,并与公式对应。
# denoiser.py
z = self.noise_scale * torch.randn(bsz, 3, H, W, device=device)
timesteps = torch.linspace(0.0, 1.0, self.steps + 1, device=device) \
.view(-1, *([1] * z.ndim)).expand(-1, bsz, -1, -1, -1)
K = steps)。_forward_sample)# denoiser.py
x_cond = self.net(z, t.flatten(), labels)
v_cond = (x_cond - z) / (1.0 - t)
x_uncond = self.net(z, t.flatten(), torch.full_like(labels, self.num_classes))
v_uncond = (x_uncond - z) / (1.0 - t)
interval_mask = (t < high) & ((low == 0) | (t > low))
cfg_scale = torch.where(interval_mask, self.cfg_scale, 1.0)
v_guided = v_uncond + cfg_scale * (v_cond - v_uncond)
对应关系:
num_classes 类)分支。# Euler
z_{k+1} = z_k + (t_{k+1} - t_k) * v_guided(z_k, t_k)
# Heun
z^{(euler)}_{k+1} = z_k + (t_{k+1} - t_k) * v_guided(z_k, t_k)
z_{k+1} = z_k + (t_{k+1} - t_k) * 0.5 * (v_guided(z_k, t_k) + v_guided(z^{(euler)}_{k+1}, t_{k+1}))
Heun 相当于显式两次评估的二阶 Runge-Kutta,能在保持速度场一致的同时,提高收敛稳定性。
# engine_jit.py::evaluate
sampled_images = model_without_ddp.generate(labels) # ∈ [-1,1]
sampled_images = (sampled_images + 1) / 2 # 归一化到 [0,1]
在评估/采样脚本中,会把结果映射回 [0,1] 再乘 255 保存成 PNG,同时确保各类别数量一致(详见 engine_jit.py::evaluate)。
填写你实际测得的 FID / IS:
| 指标 | 数值 | 备注 |
|---|---|---|
| FID ↓ | xx.x | 与 jit_in256_stats.npz 对比 |
| Inception Score ↑ | xx.x | 使用 torch-fidelity |
| 采样步数 | 50 | Heun ODE |
| CFG | 2.9 (区间 0.1–1.0) | 仅中后期启用 |
| 指标 | 数值 | 备注 |
|---|---|---|
| FID ↓ | xx.x | 与 jit_in512_stats.npz 对比 |
| Inception Score ↑ | xx.x | |
| 采样步数 | 50 | Heun ODE |
| CFG | 2.9 (区间 0.1–1.0) |
下列对比基于 denoiser.py、model_jit.py、engine_jit.py 以及论文 Li & He (2025) 中的描述整理。
传统扩散:DDPM/EDM/DiT 通常需要显式的 $\beta_t$ 或 $\sigma_t$ 调度表,定义 $x_t = \alpha_t x_0 + \sigma_t \epsilon$,并在训练/推理中都依赖该 schedule。
JiT:直接采样 $t \sim \mathrm{sigmoid}(\mathcal{N}(P_{\text{mean}}, P_{\text{std}}^2))$(见 denoiser.py::sample_t),用插值
$$
z = t x + (1-t) e
$$
构造“噪声图像”。这种折线式的时间参数化摒弃了复杂的噪声表,呼应论文中“回归到最简单的去噪建模”的观点。
传统扩散:大多预测噪声 $\epsilon$、干净图 $x_0$ 或 EDM 风格的 $v$,但仍以预定义的噪声 schedule 为前提。
JiT:直接以
$$
v = \frac{x - z}{1 - t}
$$
作为唯一监督量(denoiser.py::forward),并要求网络回归 $v_\theta(z,t,y)$。原论文强调该“速度视角”可以让推理过程完全复用训练时的物理量,从而更稳定。
传统扩散:逆扩散链往往需要在每一步添加噪声(DDPM)或使用复杂的 $\sigma$ 网格进行 SDE/ODE 求解(EDM、DDIM)。
JiT:在 $t \in [0,1]$ 上等步长积分
$$
z_{k+1} = z_k + (t_{k+1} - t_k)\, v_\theta(z_k, t_k)
$$
可选 Euler 或 Heun(_euler_step / _heun_step),完全确定性,不再向链中重新注入噪声。如此一来,生成轨迹与论文中的“ODE 形式的纯去噪过程”保持一致。
传统扩散:多采用带跳连的 U-Net 主干,或在 DiT 中只在高分辨率中段使用 Transformer。
JiT:通篇使用 ViT 风格的 Transformer(见 model_jit.py::JiT),特点包括:
BottleneckPatchEmbed 将像素直接映射到 token;VisionRotaryEmbeddingFast 贯穿全程,并为 in-context tokens 预留槽位;FinalLayer 做 AdaLN 调制;传统扩散:常见做法是把 class embedding 加到所有 token,或引入单个 class token,CFG 对所有时间步使用统一倍率。
JiT:
in_context_start 个 block 前插入长度为 in_context_len 的 “label prompts”(JiT.forward 第 348~354 行),模拟 in-context learning;num_classes 类(LabelEmbedder + drop_labels);_forward_sample),可在早期鼓励多样性、在后期强化语义,对齐论文中提出的“逐段调节条件强度”策略。传统扩散:往往需要配套的噪声 schedule 配置器、EMA 切换脚本、独立的采样器模块等。
JiT:训练和评估逻辑被整合在极少数文件中:
main_jit.py:解析配置、创建 Denoiser、分布式训练;engine_jit.py:只有一个训练循环和一个评估函数,评估时会自动切换 EMA 权重;denoiser.py:统一实现了损失、采样、CFG 以及 EMA 更新;# 训练示例
torchrun --nproc_per_node=8 \
main_jit.py \
--model JiT-B/16 \
--P_mean -0.8 --P_std 0.8 \
--img_size 256 --noise_scale 1.0 \
--batch_size 128 --blr 5e-5 \
--epochs 600 --warmup_epochs 5 \
--gen_bsz 128 --num_images 50000 \
--cfg 2.9 --interval_min 0.1 --interval_max 1.0 \
--data_path ${IMAGENET_PATH} --online_eval
# 评估示例
torchrun --nproc_per_node=8 \
main_jit.py \
--model JiT-B/16 \
--img_size 256 --noise_scale 1.0 \
--gen_bsz 128 --num_images 50000 \
--cfg 2.9 --interval_min 0.1 --interval_max 1.0 \
--resume ${CKPT_DIR} --evaluate_gen
本页面可作为 JiT 复现实验的展示页:提供可视化、定量指标以及与传统扩散的差异说明。
建议:将当前 HTML 放在仓库里(例如 docs/results.html),并在 README 中加链接,方便快速查看。